Infinite pages and escaping crawl traps
Note: this isn't an article about redirect loops, nor encompassing of all types of crawl traps. Rather a niche case study of my own experiences.
For the inaugural post, I'll be exploring infinite pages and crawl traps. Not a new topic (see here and here for some handy in-depth guides), yet I've dealt with the same specific version of this issue on two occasions, which I think gives me a modicum of authority to shed some helpful advice on the matter.
In short, I'll be discussing infinite URL paths occurring on parameterised URLs... on pages that don't incorporate parameterisation.
Confused? Exactly. permalink
The two times I ran into crawl traps were the result of code changes, which happened to be introduced during site re-designs. The first instance happened after migrating existing landing pages to a new CMS (Site A). The other occurred after an entire site was migrated to a custom Wordpress theme, although the issue only happened on category pages with pagination (Site B).
Enough waffle, let me illustrate the scenario...
Googlebot finds an alternative version of a category URL (for the sake of example we'll use /lyfehacks/, which was an idea for a parody site I once had that never came to fruition) at the following address:
/lyfehacks/?random_parameter=wtf
This parameter isn't used on the site, and doesn't even change the content. The page is exactly the same as its canonical equivalent.
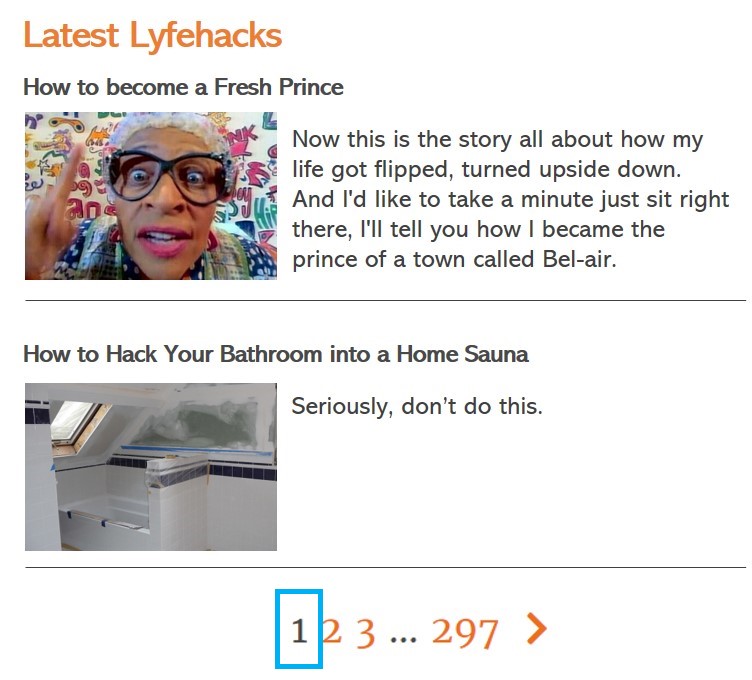
All links on the page reflect the correct URL environments apart from paginated links, which still include ?random_parameter=wtf. Subsequently, that query is injected into the /page/ path as follows:
/lyfehacks/?random_parameter=wtfpage/2/
Googlebot accesses 'page 2', yet the content remains the same.
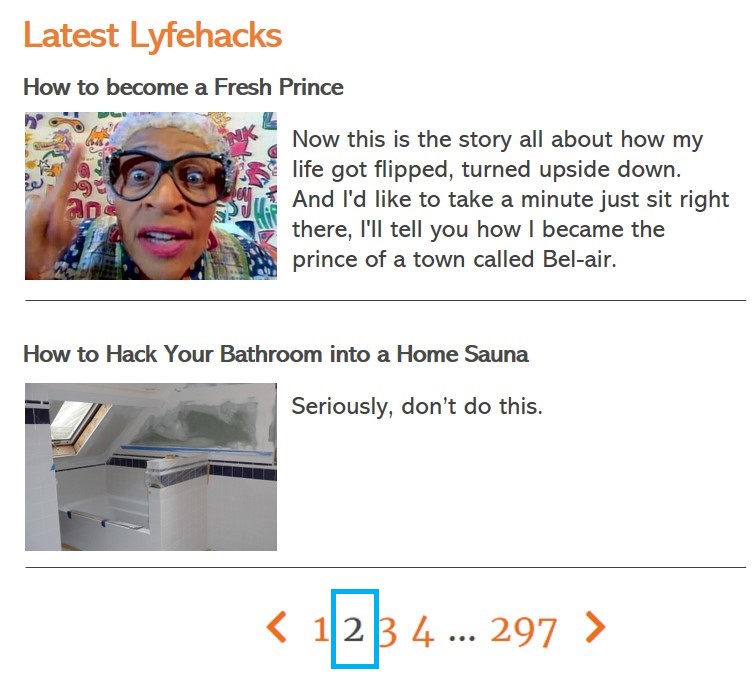
This is because the consolidation of ?random_parameter=wtf and page are effectively treated like a unique parameter ID, rather than a relative link.
And so Googlebot continues to spider the paginated links. It accesses the next page:
/lyfehacks/?random_parameter=wtfpage%2F2%2Fpage/3/
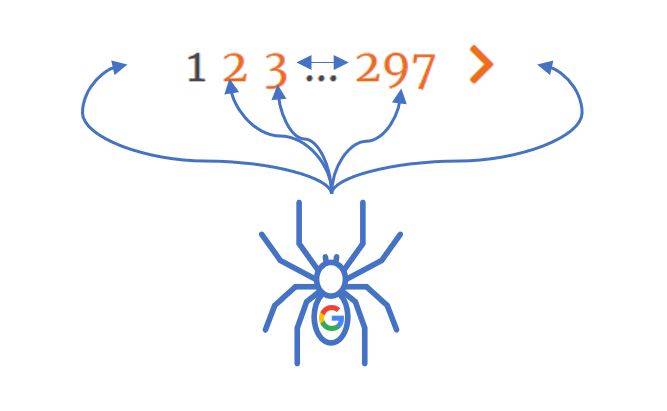
Each new page path is appended to the previous ones, while all 'page' and number sub-directories that came before are injected into an ever-evolving (and entirely junk) query string.
/category/?random_parameter=wtf%2Fpage%2F6%2Fpage%2F2%2Fpage%2F2page%2F3%2Fpage%2F2%2Fpage%2F297%2F%2Fpage%2F6%2Fpage%2F2%2Fpage%2F2page%2F3%2Fpage%2F2%2Fpage%2F297%2Fpage/297/
As you can expect, duplicate content hell with a fine dollop of wasted crawl budget on top.
Finding the trap permalink
Focusing on Site A for the moment, the issue was initially discovered via the server logs where I noticed a massive spike in Googlebot activity. 98% of requests were concentrated on infinite, non-existent pages, all of which were specific landing page types and rooted to a handful of unknown parameters.
This was simultaneously mirrored in Search Console's Coverage reports, which showed an increasing numbers of crawlable indexed URLs. Despite applying noindex,nofollow, Google only paid attention to the noindex bit. Access logs continued to show Googlebot getting lost down the infinite page rabbit hole.
Believe me when I say it got ridiculous...
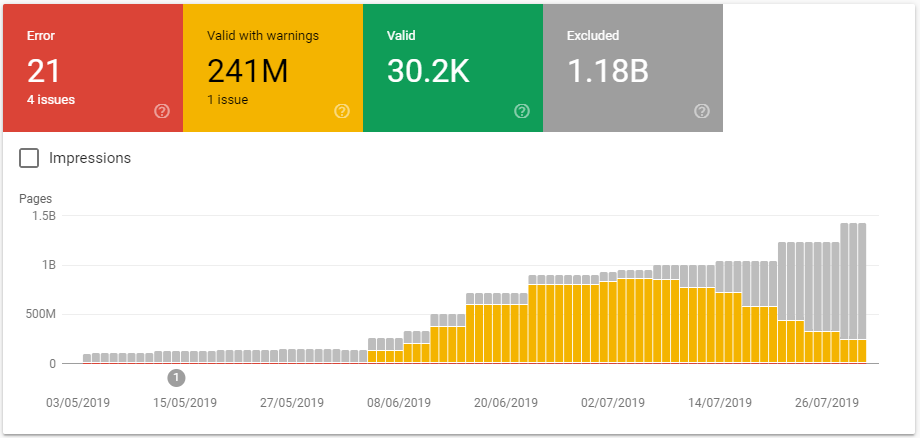
And this almost certainly wasn't the full picture.
Why is this a problem? permalink
The amount of possible 'infinite URL' variations that Googlebot can discover are extrapolated based on the number of categories (other other page types) within your taxonomy (think locations, car models or clothing based categories for the most extreme examples). The bigger the site and number of pages, the bigger the trap for crawlers to get lost in and less budget being assigned to the meaningful stuff.
Even on Site B (which consists of roughly 6k indexable pages), paginated links on categories led to +1million pages being crawled (like in the example shown above).
Escaping the trap permalink
Turning attention to Site A again, it took a while to figure out the root cause of how these URLs came into existence in the first place. After briefly wondering if we'd been spammed, I eventually discovered a handful of sites in the backlink data that were linking with (what appeared to be) custom tracking parameters, which matched those in the server logs and Search Console coverage reports.
Meanwhile on Site B, all infinite URLs included the ?ak_action=reject_mobile query string, which belongs to the Jetpack plugin when Mobile Theme is enabled. Jetpack is no longer used by this site and, like Site A, the parameters are some weird legacy stuff that Googlebot has cached.
The exact query strings aren't wholly important. Although it's handy to understand where they've come from, while being sure you're dealing with parameters that aren't useful in the current version of your site (eg. faceted navigation or other means of changing content). Regardless, any query string will lead to the same outcome.
Solving the issue initially took some time. As mentioned before, Google respected noindex, but nofollow was ineffective. When pages eventually dropped from the index, blocking the offending parameters via robots.txt proved the best solution for stopping spiders in their tracks (walks off into the sunset).
Balance restored, but the crucial bit in all this is understanding where coding bugs exist within your site's architecture, and working with your development team to fix them.
Hopefully this has proved interesting/useful for someone. Otherwise, feel free to humblebrag if you've discovered infinite page crawls beyond the billions.
Thanks for reading.